Producător/Autor: Blei et al., 2003; Li-Jia & Fei-Fei, 2007;
Latent Dirichlet Analysis este un model utilizat pentru clusterizarea unui corpus. Poate fi implementat un proces generativ de clusterizare nesupervizată a fluxului de știri pentru determinarea automată a similarităților detectabile în corpus. Intuiția principală a acestei tehnici este că putem asocia în mod automat fiecărui cuvânt o probabilitate de a semnala un tip de similaritate între cuvinte manifestată în corpus. Ceea ce se obține este un vector de probabilități pentru fiecare cuvânt, dimensiunea vectorului fiind determinată de numărul de tipuri de similarități considerate. Intrarea este constituită de două variabile:
- Numărul de tipuri de similarități dorite.
- Corpusul de analizat.
Menționăm faptul că pentru o predicție bună de încadrare a știrilor, se poate alege un prag de până la 50 topice iar pentru definirea similarității la nivel de cuvinte – o rețea neuronală recurentă. Această clusterizare paralelă a cuvintelor, independent de topice, este cuplată la intrarea LDA pentru clusterizarea corpusului într-o manieră care reduce fenomenul data sparseness, una dintre problemele cheie în construcția învățării automate (ML) de tip n-gram, chiar și atunci când dispunem de colecții mari de texte.
Indiferent cât de mare este corpusul de antrenare, vor fi n-grame care nu vor apărea în el, însă care ar putea să apară în corpusul de testare.
Un model de limbă de tip n-gram se construiește estimând probabilitatea secvenței de cuvinte W = w1, w2, …, wn pe baza unor corpusuri de text de mari dimensiuni.
Ex: în cazul unui ML bi-gram trebuie estimate probabilitățile pentru fiecare pereche de cuvinte (wi, wj). Pentru a calcula aceste probabilități se utilizează principiul maximum likelihood. Cu alte cuvinte, se numără de câte ori cuvântul wieste urmat de cuvântul wj, comparativ cu alte cuvinte:
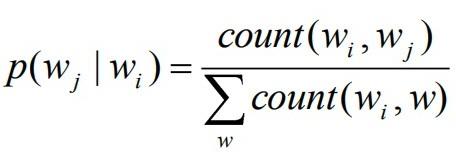
Practic, probabilitatea asignată n-gramelor necunoscute este 0.
În afară de acest caz există alte n-grame care apar de foarte puține ori (mai puțin de zece ori) în corpusul de antrenare. Această problemă devine mai importantă în cazul ML de tip n-gram de ordin mai mare. În acest caz, probabilitățile care au fost estimate pe baza numărului de apariții ale n-gramelor în corpusul de antrenare, trebuie ajustate. Cum? Prin metode de netezire.
Metodele de netezire extrag o parte din probabilitatea alocată pentru n-gramele întâlnite la antrenare și o redistribuie n-gramelor necunoscute.
În literatură întâlnim mai multe metode de netezire care particularizează modul de redistribuție a probabilității. Cea mai eficientă metodă este Good-Turing, cunoscută drept netezirea Katz.
Problema data sparseness este abordată cu metode de back-off. Pentru a crea un model de limbă interpolat, metodele back-off utilizează mai multe modele de limbă care au avantaje diferite și pot beneficia de toate părțile constituente. Cu alte cuvinte, pentru a determina probabilitatea unei n-grame care nu se regăsește în corpusul de antrenare, se poate lua în considerare și probabilitatea oferită de modelele de limbă de ordin inferior. În acest caz, problema de optimizare este reprezentată de alegerea echilibrului corect între modelele de ordin superior și cele de ordin inferior, în cazul în care acestea vor fi folosite.
Ex: Dacă modelele de tip n-gram de ordin mai mare oferă un context de predictibilitate mai mare, modelele de ordin mai mic sunt mai robuste.
O metodă de back-off eficientă în estimarea probabilităților n-gramelor necunoscutepe baza probabilităţilor asignate acestor n-grame de către modele de ordin mai mic este metoda modificată de netezire Kneser-Ney (Chen & Goodman, 1998). Aceasta folosește o metodă numită reducere absolută pentru a micșora probabilitatea cumulată a evenimentelor întâlnite.
În cazul unui corpus de știri necesar pentru prezicerea interesului public pentru anumite topice, se maximizează probabilitatea de ocurență a unui cuvânt ținând cont de contextul imediat înconjurător: outputul ar urma să fie format dintr-un set de cuvinte cheie pentru fiecare topic.
- Blei D.M., Ng A. Y., Jordan M. I. (2003), Latent Dirichlet Allocation, Journal of Machine Learning Research, 3: 993–1022.
- Li-Jia L., Fei-Fei L. (2007), What, where and who? classifying events by scene and object recognition. In: Int. Conf. of Computer Vision: 221-228.